Complex Adaptive Systems in Software
June 13, 2018
Complex Systems
Resilience
SRE
Software Development
Resilience engineering is becoming a required practice as people begin to expect services to be available nearly 100% of the time. We have the same requirements of the systems that sustain us: ecosystems, anatomical systems. Our world is one complex adaptive system after another.
If you consider our anatomy, we have redundant systems: 2 lungs, 2 kidneys, 2 halves of the brain, 2 arms, 2 legs, etc. In cases where one of the components is degraded, the other component is able to pick up some of the slack to sustain life.
Because we are building systems, we as engineers must be acutely aware of how we intend to build resilience into our systems.
What is a system?
A system is a number of connected entities. Connected in this sense could be via a TCP connection or it could be connected by an asynchronous delivery mechanism such as a queue.
What does it mean to be Complex?
Complexity is a little different in systems than in the other areas we see it in our code. We have analysis tools that can tell us if code is too complex based on certain criteria: long functions, too many if statements, etc. This is complexity within a certain scope, but complexity in systems means more connections of components. The complexity of the components themselves are irrelevant. It doesn’t matter if the component is a simple web server or a Postgres database with 1000s of partitioned tables.
In systematic complexity the number of connected components is what matters and measuring the number of “hops” between components. We’ll dive into this more in a bit.
What does it mean to be adaptive?
Adaptive systems are systems in which the behavior of the system changes in response to changes in connections and the state of those connections.
3 properties of complex systems
Unpredictability
Each component has it’s own behaviors and because of the highly connected nature of complex systems coupled with non-linear behaviors, it is not possible to determine what the state of the system will be in the future. This is why during outages and incidents multiple causes will be at play.
The unpredictability of complex systems means that we cannot predict ways in which a system will fail, so we must have contingencies for when systems fail, not if.
Susceptibility to Contagion
Anomalies in a system can spread at a rapid rate in complex systems because of the highly connected nature of them. A good example of this in software systems is “cascading failures” that start when one component fails and the failure of that component seems to spread to other components.
Modularity - Failure Domains
Modularity is that although a complex system may be highly connected, parts of the system emerge as entire failure domains. Think of your data tier. You may run a clustered database like Cassandra, MongoDB, XtraDB, Galera, or Postgres-XL. This does not insulate it from failure. Loss of quorum can lead to unavailability for example.
Modularity is defined as well as a system is connected, some parts are more connected than others.
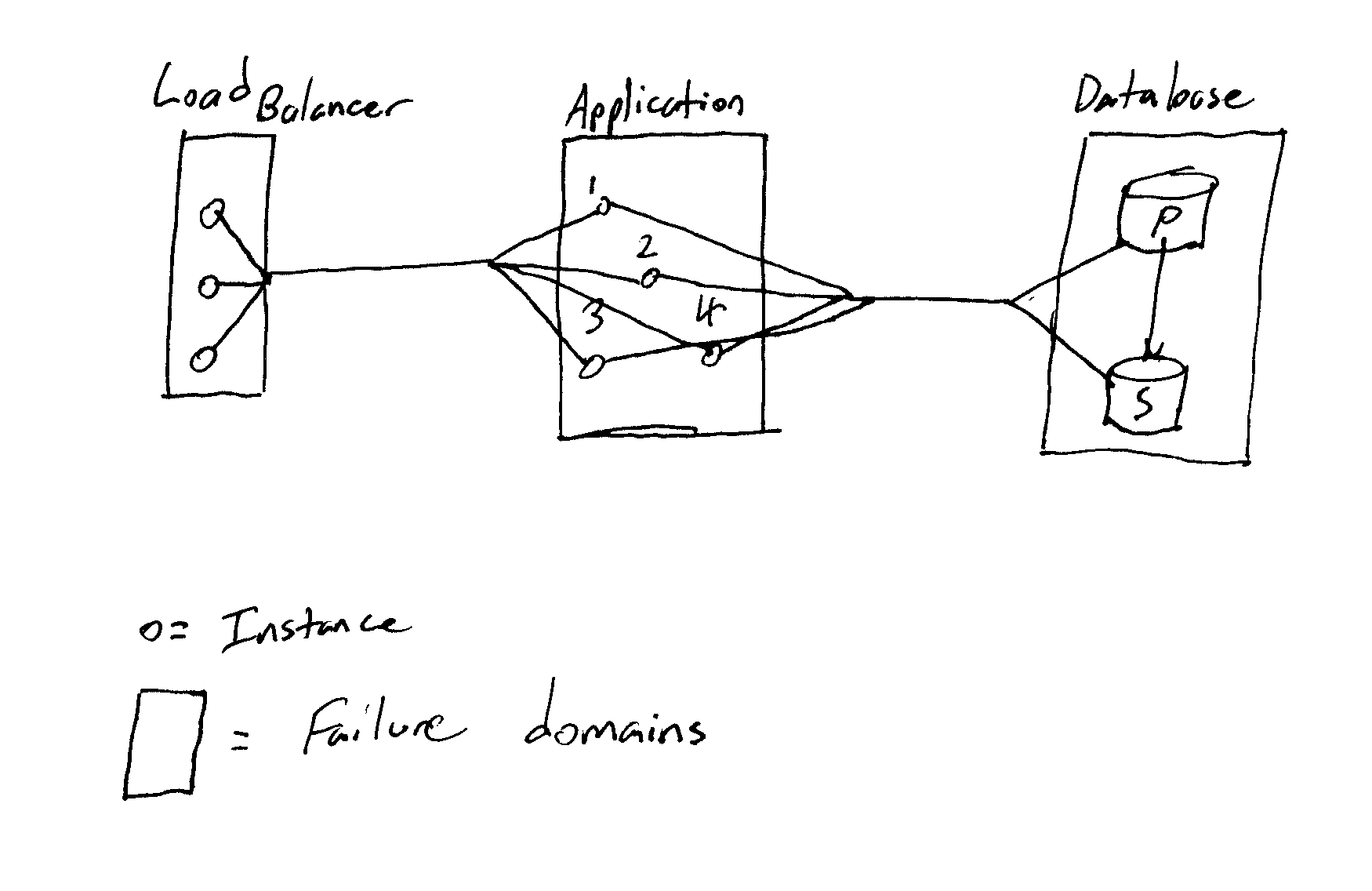 A somewhat typical application architecture
A somewhat typical application architecture
Resilience
Resilience is how we need to combat the uncertainty of a complex system. We cannot enumerate and predict all the failure modes of a system, but we can build contingencies for unavailability of any component. This is how We already build redundancy into our systems. We deploy multiple instances of software, we have active/passive configurations, etc. By employing software resiliency patterns such as circuit breakers, bulkheads, timeouts, deadlines, and fast failures (just to name a few) we can accept and embrace the modularity in systems.
Redundancy
Redundancy helps mostly with failures internal to a component. A server fails, a network is partitioned, but redundancy allows us to handle the loss. Sometimes this means needing to have awareness of other members in a clustered configuration but a server failure should not impact the availability of another component. That is where modularity and resilience patterns come in.
Define Failure Domains - Modularity
Recognizing the failure domains of a system let you define areas to employ resilience patterns against. You know that the database is a failure domain eventhough individual component failure is isolated by use of redundant instances. If the database becomes unavailable, your service can still degrade gracefully and handle failure, creating an adaptive user experience in the face of overt failure.